
December 9, 2021Computer Vision , Deep Learning , Machine Learning
Image similarity is becoming popular in recent times. The ability of an image similarity model to find identical images with the utmost accuracy in defined data sets is helping in many ways. Finding plagiarized photos, identifying fake accounts, discovering original images of people, products, and places are a few of the image similarity real-world applications. Image similarity is often concluded as the same as image classification by many. However, the similarity model unlike image classification is completely unsupervised and operates beyond labeling images for model creation.
Image similarity vs Image Classification
Image similarity is closely related to image classification application, as both models use the same classifier networks for the processing and delivering the expected outcomes. However, there are a few differences to consider.
- Image similarity considers many dimensions while figuring out whether or not an image is found similar by considering one or possibly several discrete categories.
- Image classifiers are always learned to be implicit due to poor training. If you train a classification model to recognize bicycles, scooters, and cars, and you didn’t expect to classify anything else. Then, there is a possibility that the model will predict motorcycles as bicycles or scooters, which is not acceptable.
- Image similarity models are trained differently, using labels to indicate if two images are similar or not, and training networks with similarity relationships can range between every pair of images in a dataset to only between a few necessary. Thanks to constructive losses, the trained model can be flexible to recognize other images known to be similar in the data set instead of finding out only defined or fixed categories.
Introduction to Image Similarity/Reverse Image search Model
An image similar search or reverse image search is a Deep CNN model which identifies the top N similar images from a given image based on the input provided for search. How does it work? Well, every image stored in our computer is in the form of numbers or vectors that describe the image completely (which is also known as Image Vector). A CNN is trained to map images and extract meaningful features out of the images into the vectors. And further, we use the vectors as word embeddings to compute how similar one image is to another.
Creating a Model
The key ideas in building an image similarity model are:
Stage 1: Use a pre-trained CNN classifier with a large, general dataset. A good example is ImageNet, with a minimum of 1000 categories and 1.2 million images.
Stage 2: With a CNN classifier the outputs of each layer can be viewed as a meaningful vector representation of each image. Extract these feature vectors from the layer before the output layer on each image of your task.
Stage 3: Create a nearest neighbors model with the feature vectors extracted as input.
Below we have described the above-mentioned steps with each process explanation and important steps to be considered in building an image similarity model.
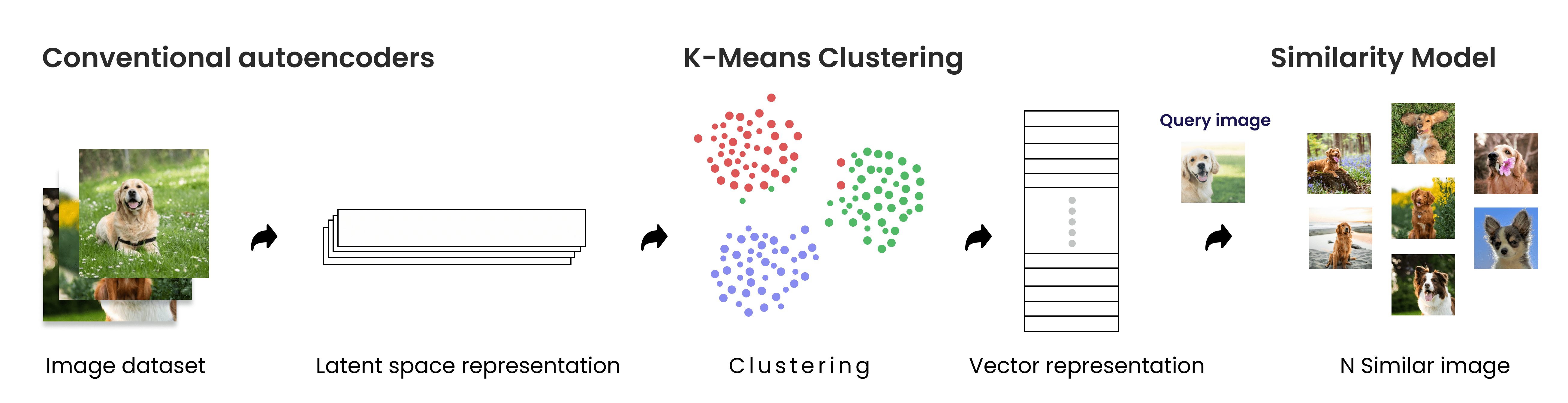
Stage 1: Data Extraction and Normalization
Download a general dataset, with the maximum amount of images for training an image similarity model. As every task of ML/DL is related to playing a key role in model training and to improve its accuracy with test data, It is important to tune model hyperparameters that are splitting of data. And for that task, we need data that is taken from model training in a small portion like 1–2% referred to the size of data that needs to be processed and this can be referred to as a data cross-validation or simply data validation.
Running through all the images in the data set and splitting that list into train and test data. Eliminates the need of splitting the data again in the future and the need for repetitive tasks. Performing the series of following actions for reading the images from both train and test datasets, we can conclude the data normalization.
- Reading images using the open cv2 module.
- Converting images with BGR (Blue, Green, red) into RGB (Red, Green, Blue)
- Resizing image shape and normalizing the training data.
Stage 2: Convolutional AutoEncoders
Convolutional Autoencoders(CAEs) are a type of convolutional neural network primarily used to build the deep CNN models for machine learning. The main difference between the other neural networks and CAEs is convolutional autoencoders are unsupervised learning models in which the former model is trained from end-to-end to learn filters and combine these learnings as knowledge to classify their input.
CAEs try to keep the spatial information of the input image data as it is and extract output information gently, when the restorations seem satisfactory.
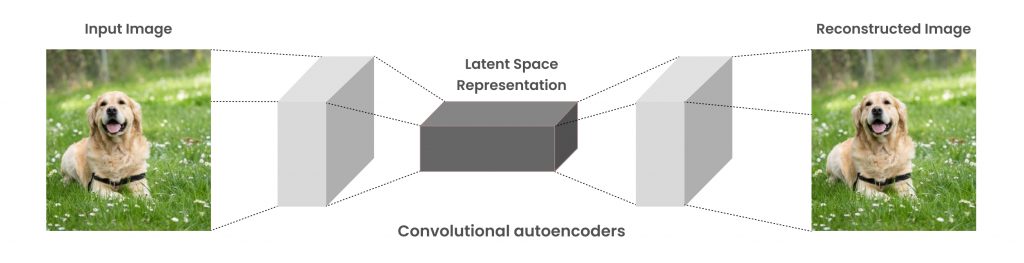
For instance, Images on the left side are original images whereas images on the right side are restored from compressed representation. We can move on to the final step identifying similar images in the given data set.
Stage 3: similarity K-means Clustering and Model Testing
After getting compressed data representation of all images that need to be identified, we hereby can apply the K-Means clustering algorithm to a group of the images at different levels of clusters. This helps us to label the unidentified data. After clustering the unclustered data and getting all the available data labeled. And as a final process, we can perform the K-NN algorithm to find similar images(Nearest Neighbors). Using KNN model finding N similar images using predict images and finally plotting the result
As we conclude, image similarity is experiencing tremendous growth due to increasing demand for this technology in recent years. However, businesses are still limited to using this technology for identity verification, eCommerce applications, cybersecurity, fraud detection, and prevention, etc. DeepLobe team can potentially help organizations working in the commercial or industrial space with the application of image similarity. To know more about image similarity or any other computer vision application, contact us.
