
April 28, 2021Artificial Intelligence , Deep Learning
Image Segmentation is considered a vital task in Computer Vision – along with Object Detection – as it involves understanding what is given in the image at a pixel level. It provides a comprehensive description that includes the information of the object, category, position, and shape of the given image. There are various algorithms for Image Segmentation that have been developed with applications such as scene understanding, medical image analysis, robotics, augmented reality, video surveillance, etc. The advent of Deep Learning in Computer Vision has diversified the capabilities of the existing algorithms and paved the way for new algorithms for pixel-level labeling problems such as Semantic Segmentation. These algorithms learn rich representations for the problem, including automatic pixel labeling of images in an end-to-end fashion.
This blog explores the depths of Semantic Segmentation while discussing the relevant use-cases and how to use convolutional neural network architectures involved in achieving the results and metrics to understand the image, its contents/objects, and where are these objects located in the image.
First, let’s get acquainted with the basics. So, how is Image Segmentation different from Image Classification and Object Detection?
While the Image Classification models classify all the objects in an image into a single class, the segmentation models provide the exact outline of each object of a single class – pixel by pixel, giving us a fine-grain understanding of the objects in the image. In Object Detection, the models build bounding boxes corresponding to each class in the image and also specify the location of multiple objects in the image.
The Emergence of Deep Learning in Image Segmentation
The recent advancements in deep learning have resulted in the emergence of high-performance algorithms to interpret images – such as object detection, semantic segmentation, instance segmentation, etc. Deep Learning algorithms based on neural networks can acquire a high generalization ability to identify and recognize images as neural networks can learn the high dimensional features of the objects from large training datasets. These models can understand and analyze images that they have not seen before.
Types/Techniques of Image Segmentation
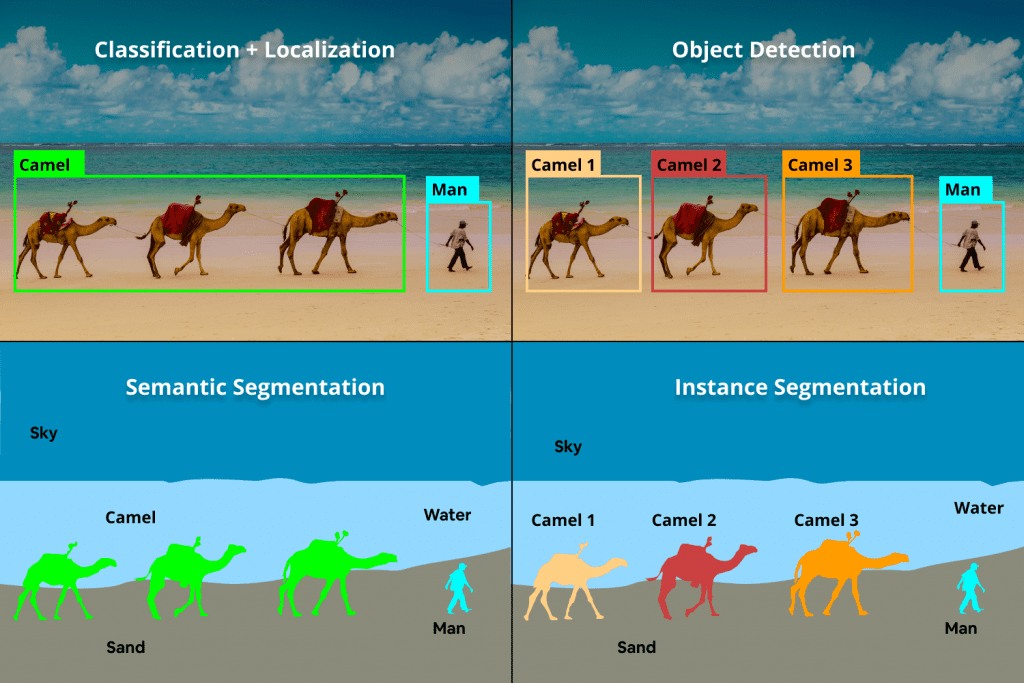
There are two categories in which the Image Segmentation tasks can be divided into semantic segmentation and instance segmentation.
In semantic segmentation, every pixel of an image is associated with a class label as it treats multiple objects of the same class as a single entity. For example, in the above image, there are classes labeled as “camel”, “man”, “water”, “sand”, “sky” and any pixel belonging to any camel is assigned to the same “camel” class.
Instance segmentation treats multiple objects of the same class as distinct individual instances. For example, each sheep in the above image would be assigned to the “camel” class but would be given a distinct color as they are different instances of the class.
Semantic Segmentation – Use cases & Applications
Robotics- Segmentation models train and deploy the robots to map and interpret the environment in which they work in order to perform efficiently. Deep learning algorithms overtake the traditional methods of segmentation by applying a trained deep classifier on each pixel region to determine its semantics.
Handwriting recognition – Character segmentation has become crucial and segmenting a handwritten text document into individual characters is important for document analysis, and many other areas.
Autonomous/self-driving cars – Self-driving cars need to see, interpret, and respond to a scene in real-time and, hence, need a complete understanding of their surroundings to a pixel-perfect level. Thus, semantic segmentation is used to identify lanes, vehicles, people, traffic, obstacles, and other objects.
Medical imaging and diagnostics – A large number of segmentation techniques have been adapted for medical image processing where these techniques separate homogeneous areas that may include important pixels of organs, lesions, etc., and identify abnormalities.
Basic structure, methods, and techniques
As mentioned earlier in this blog, the advancements in Deep Learning have enabled a better and comprehensive way of handling image-related problem statements, when compared to classical Machine Learning techniques like SVM, Random Forest, K-means clustering, etc. The basic structure of the semantic segmentation models should have the same underlying backbone, setup, and flow so that it can be present in all the existing state-of-the-art methods as well as the new methods.
It is known that Deep Neural Networks transform Computer Vision. It surpasses its predecessors like classical Machine Learning techniques by a big margin.
The model architecture comprises several layers of convolutional, non-linear activations, batch normalization, and pooling where the initial layers learn the concepts such as edges and colors that are at a lower level. The later level layers learn about concepts such as different objects. Let’s dig deeper into the basic structure of semantic segmentation models by taking into consideration the below points to define our problem:
– A class and a color must be assigned to each pixel of the image.
– The input and output images should be of the exact same sizes.
– Each pixel from the input image must correspond to a pixel in the exact same location as the output image.
– A pixel-level accuracy is needed to distinguish between different classes.
The goal is to take either an RGB color image (height×width×3) or a grayscale image (height×width×1) and output a segmentation map where each pixel contains a class label represented as an integer (height×width×1).
For a better and clear understanding, the image given below is taken as the input image in this article.

Street_Image.jpg
Fully Convolutional Network (FCN)
A traditional methodology towards developing a neural network architecture design for this assignment is to just stack a few convolutional layers (with similar cushioning to safeguard measurements) and yield a last division map. This straightforwardly takes in planning from the information picture to its comparing division through the progressive change of highlight mappings; be that as it may, it’s computationally costly to safeguard the full goal all through the organization.
The overall design of a CNN comprises not many convolutional and pooling layers followed by barely any completely associated layers toward the end. The completely associated layer can be considered as doing a 1X1 convolution that covers the whole area.
The FCNs consist of just convolutional and pooling layers, without the need completely associated. The first methodology was to utilize a pile of same-sized convolutional layers to plan the info picture to the yield one.
Input files and the project directory
The following image is the output. The FCN ResNet50 model worked pretty well by segmenting all the people into light red color, bus into green color, and cars into grey. The results are not perfect, though, as the telephone booth on the left is segmented as a bus and is masked with green color and people behind the bus are not masked at all. It is to be noted that this could be because of various known and unknown reasons and in such situations may be using a bigger model like FCN ResNet101 will yield better results.

Street_Image.jpg – Segmented output image after applying FCN ResNet model
Summary
This article applies Deep Learning-based semantic segmentation models on images where the FCN ResNet50 model with the PyTorch Deep Learning model was used to mask the segmented classes. It is clear that semantic segmentation is a new and active field of research and image semantic segmentation is a recent achievement in the world of deep neural networks for the reason that the combination of Computer Vision and Deep Learning is gaining popularity and progress in tackling complicated tasks.
For any further information, clarifications, or queries, feel free to contact us.
Image Segmentation is considered a vital task in Computer Vision – along with Object Detection – as it involves understanding what is given in the image at a pixel level. It provides a comprehensive description that includes the information of the object, category, position, and shape of the given image. There are various algorithms for Image Segmentation that have been developed with applications such as scene understanding, medical image analysis, robotics, augmented reality, video surveillance, etc. The advent of Deep Learning in Computer Vision has diversified the capabilities of the existing algorithms and paved the way for new algorithms for pixel-level labeling problems such as Semantic Segmentation. These algorithms learn rich representations for the problem, including automatic pixel labeling of images in an end-to-end fashion.
This blog explores the depths of Semantic Segmentation while discussing the relevant use-cases and how to use convolutional neural network architectures involved in achieving the results and metrics to understand the image, its contents/objects, and where are these objects located in the image.
First, let’s get acquainted with the basics. So, how is Image Segmentation different from Image Classification and Object Detection?
While the Image Classification models classify all the objects in an image into a single class, the segmentation models provide the exact outline of each object of a single class – pixel by pixel, giving us a fine-grain understanding of the objects in the image. In Object Detection, the models build bounding boxes corresponding to each class in the image and also specify the location of multiple objects in the image.
The Emergence of Deep Learning in Image Segmentation
The recent advancements in deep learning have resulted in the emergence of high-performance algorithms to interpret images – such as object detection, semantic segmentation, instance segmentation, etc. Deep Learning algorithms based on neural networks can acquire a high generalization ability to identify and recognize images as neural networks can learn the high dimensional features of the objects from large training datasets. These models can understand and analyze images that they have not seen before.
Types/Techniques of Image Segmentation
There are two categories in which the Image Segmentation tasks can be divided into semantic segmentation and instance segmentation.
In semantic segmentation, every pixel of an image is associated with a class label as it treats multiple objects of the same class as a single entity. For example, in the above image, there are classes labeled as “camel”, “man”, “water”, “sand”, “sky” and any pixel belonging to any camel is assigned to the same “camel” class.
Instance segmentation treats multiple objects of the same class as distinct individual instances. For example, each sheep in the above image would be assigned to the “camel” class but would be given a distinct color as they are different instances of the class.
Semantic Segmentation – Use cases & Applications
Robotics- Segmentation models train and deploy the robots to map and interpret the environment in which they work in order to perform efficiently. Deep learning algorithms overtake the traditional methods of segmentation by applying a trained deep classifier on each pixel region to determine its semantics.
Handwriting recognition – Character segmentation has become crucial and segmenting a handwritten text document into individual characters is important for document analysis, and many other areas.
Autonomous/self-driving cars – Self-driving cars need to see, interpret, and respond to a scene in real-time and, hence, need a complete understanding of their surroundings to a pixel-perfect level. Thus, semantic segmentation is used to identify lanes, vehicles, people, traffic, obstacles, and other objects.
Medical imaging and diagnostics – A large number of segmentation techniques have been adapted for medical image processing where these techniques separate homogeneous areas that may include important pixels of organs, lesions, etc., and identify abnormalities.
Basic structure, methods, and techniques
As mentioned earlier in this blog, the advancements in Deep Learning have enabled a better and comprehensive way of handling image-related problem statements, when compared to classical Machine Learning techniques like SVM, Random Forest, K-means clustering, etc. The basic structure of the semantic segmentation models should have the same underlying backbone, setup, and flow so that it can be present in all the existing state-of-the-art methods as well as the new methods.
It is known that Deep Neural Networks transform Computer Vision. It surpasses its predecessors like classical Machine Learning techniques by a big margin.
The model architecture comprises several layers of convolutional, non-linear activations, batch normalization, and pooling where the initial layers learn the concepts such as edges and colors that are at a lower level. The later level layers learn about concepts such as different objects. Let’s dig deeper into the basic structure of semantic segmentation models by taking into consideration the below points to define our problem:
– A class and a color must be assigned to each pixel of the image.
– The input and output images should be of the exact same sizes.
– Each pixel from the input image must correspond to a pixel in the exact same location as the output image.
– A pixel-level accuracy is needed to distinguish between different classes.
The goal is to take either an RGB color image (height×width×3) or a grayscale image (height×width×1) and output a segmentation map where each pixel contains a class label represented as an integer (height×width×1).
For a better and clear understanding, the image given below is taken as the input image in this article.
Street_Image.jpg
Fully Convolutional Network (FCN)
A traditional methodology towards developing a neural network architecture design for this assignment is to just stack a few convolutional layers (with similar cushioning to safeguard measurements) and yield a last division map. This straightforwardly takes in planning from the information picture to its comparing division through the progressive change of highlight mappings; be that as it may, it’s computationally costly to safeguard the full goal all through the organization.
The overall design of a CNN comprises not many convolutional and pooling layers followed by barely any completely associated layers toward the end. The completely associated layer can be considered as doing a 1X1 convolution that covers the whole area.
The FCNs consist of just convolutional and pooling layers, without the need completely associated. The first methodology was to utilize a pile of same-sized convolutional layers to plan the info picture to the yield one.
Input files and the project directory

Step 1 – is to Create a Label Color Map List
The code below is for the label_color_map.py file.

Note: In the above code block, different color map tuples (RGB format) are assigned to each class. Usually, black color is given to the background class. The class for each color is shown in the comments. This list of tuples is restricted only to this python file.
Pre-trained models for semantic segmentation are provided by PyTorch and utilizing these models makes the task of this study much easier. FCN ResNet50, FCN ResNet101, DeepLabV3 ResNet50, and DeepLabV3 ResNet101 are some of these models.
Of all the models, the FCN ResNet50 model is the most relevant model here as the backbone is ResNet50 and for the same reason it can be run on videos too – though they may not be of very high frames per second (FPS).
Dataset
The models have been trained on the COCO 2017 dataset. They are not trained in all the COCO classes (almost 80% but are trained on the 20 classes available in the Pascal VOC dataset, like mentioned below:

Step 2 – is to name Image Segmentation Utilities
It’s time to write some image segmentation utilities and functions, the codes of which are reusable, and therefore, it is recommended to keep them in a separate python script.
The below code will go into the segmentation_utils.py file.

Defining the Image Transforms: To define and normalize the images, use mean = (0.485, 0.456, 0.406) and std = (0.229, 0.224, 0.225).

In order to normalize all the images, they have been converted to tensor first.
Defining the two helper functions:
The next step is to define three different helper functions that perform the most logical part of the deep learning-based image segmentation. They are:
1. The get_segment_labels() function: This function takes three parameters as input – an image, a segmentation model, and the computation device.

2. The image_overlay() function: This function will apply the segmented color masks on top of the input image for a better interpretation of the output and also to analyze how good the deep learning model is segmenting the images.

3. The draw_segmentation_map() function: This function will apply the color masks as per the tensor values in the output dictionary from the get_segment_labels() function.

Step 3 – is to write code for Deep Learning based image segmentation
To apply Deep Learning image segmentation, certain modules need to be imported from various libraries. This code will be saved in the segment.py file.

To construct the argument parser, the script needs only one argument while execution, and that argument is the path of the image on which segmentation has to be applied.

To initialize the model, the model has to be downloaded or loaded from the disk and then evaluated and loaded onto the computation device.

Reading the image and applying segmentation to the image needs a forward pass before applying the color masks for different classes identified in the image.

Step 4 – is to overlay the image and save it to Disk
Finally, overlaying the segmented mask on the original image is just one line of code. The final result is saved on the disk using a new variable created by the name save_name.

Step 5 – is to execute the segment.py file
To execute this file, open the command line/terminal and `cd` into the project directory to look at how the image “Street_Image.jpg” has been segmented with Deep Learning.

The following image is the output. The FCN ResNet50 model worked pretty well by segmenting all the people into light red color, bus into green color, and cars into grey. The results are not perfect, though, as the telephone booth on the left is segmented as a bus and is masked with green color and people behind the bus are not masked at all. It is to be noted that this could be because of various known and unknown reasons and in such situations may be using a bigger model like FCN ResNet101 will yield better results.
Street_Image.jpg – Segmented output image after applying FCN ResNet model
Summary
This article applies Deep Learning-based semantic segmentation models on images where the FCN ResNet50 model with the PyTorch Deep Learning model was used to mask the segmented classes. It is clear that semantic segmentation is a new and active field of research and image semantic segmentation is a recent achievement in the world of deep neural networks for the reason that the combination of Computer Vision and Deep Learning is gaining popularity and progress in tackling complicated tasks.
For any further information, clarifications, or queries, feel free to contact us.
