June 10, 2021Deep Learning , Machine Learning
Text-based image retrieval (TBIR) systems use language in the form of strings or concepts to search relevant images. Computer Vision and Deep Learning algorithms analyze the content in the query image and return results based on the best-matched content. With the rapid advancement in Computer Vision and Natural Language Processing(NLP), understanding the semantics of text and images becomes mandatory as Computer Vision trains computers to interpret and understand the visual world whereas NLP gives machines the ability to read, understand, and derive meaning from human languages. These machines accurately identify and classify objects by using digital images and analyze them with deep learning models.
With Computer Vision and Natural Language Processing(NLP) gaining a lot of momentum in the recent technological developments, cross-modal network learning for image-text similarity plays a very important role in the task of a query(image/text) based image retrieval as the application of image-text semantic mining can be harnessed using the cross-modal network. This blog focuses on text or referral, expression-based queries to rank and retrieve semantically similar images.
We attempted to explore the semantic similarity between the visual and text features that can be used to further research on object and phrase localization areas by building a cross-modal similarity network that uses Triplet loss to train and use Cosine similarity to generate K-similarity scores for a given text query. The dataset that we used for this problem is the Flickr8k dataset.
Let’s dive into building the machine learning pipeline that involves
– Data understanding and preparation
– Image and text embedding extraction
– Similarity network
– Triplet loss
– Training and evaluation
Data understanding and preparation
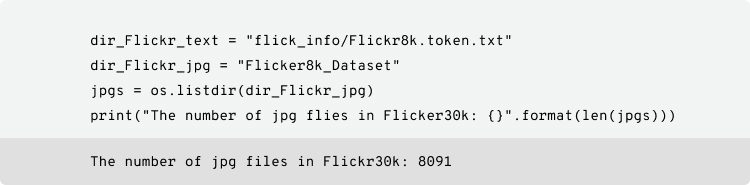
We are using Flickr dataset as it is smaller and the image resolution considered is 224X224X3. Flickr dataset has two sections containing the images and their corresponding matching captions. The dataset contains a total of 8092 images in JPEG format with different shapes and sizes, of which 6000 are used for training, 1000 for the test, and 1000 for development. Flickr8k text contains text files describing the training set, test set. Flickr8k.token.txt contains 5 captions for each image i.e. total of 40460 captions.
Below are the code snippets for loading the data, checking the number of images and number of captions per image, plotting the image with its corresponding captions for 4 images.
– The total number of images is 8091.
– The number of captions per image is 5.



The plot of 4 random images with corresponding captions are shown below:
 Get image embedding
Get image embedding
 Get image embedding
Get image embeddingExtraction of visual features is done by using a pre-trained model on ImageNet. ImageNet pretraining is an auxiliary task in Computer Vision problems. It is formally a project aimed at manually labeling and categorizing images into almost 22,000 separate object categories for the purpose of Computer Vision research. The state-of-the-art pre-trained networks included in the Keras core library demonstrate a strong ability to generalize images in real-life scenarios via transfer learning, such as feature extraction and fine-tuning.
There are various pre-trained models like VGG-19, RESNET, etc. Here we are using ResNet 50 for getting the image vectors. We need only the embedding vector, so we will not be using the entire network. Instead, we will use it until the “conv5_block3_3_conv” layer finally gives a 2048 sized embedding.
Below is the code snippet for extracting the image embeddings.

In order to further optimize the performance of the model, instead of loading the entire image into the embedding model let us try and create mini-batches that yield a pool of image sets. Online preprocessing is applied on these mini-batches by converting the image into an n-dimensional array of pixel values, which are further normalized and passed into the CNN model that we considered from ResNet50 for prediction. The resultant output is the image embedding for the pool of images generated by the mini-batch creator. Online batch creation is the idea of yielding the preprocessed images on the fly based on the batch size mentioned.
Get text embedding
For text embedding, individual words are represented as real-valued vectors in a predefined vector space where each word is mapped to one vector. The text embedding technique is often merged into the field of Deep Learning as the vector values are learned in a way that resembles a neural network. The distributed representation, based on the usage of words, captures their meaning by allowing words used in similar ways to result in having similar representations.
There are various pre-trained models, like Glove, SkipThoughts, etc, to get text embedding performed. The model we are considering is the Glove pre-trained model that derives the relationship between the words. It considers the global statistics-GloVe 300-dimensional vectors trained on the 42B token common crawl corpus.
The idea is to create a representation of words that capture the meanings, semantic relationships, and the contexts that they are used in. This will help us to achieve transfer learning. Transfer learning could be either about the words or about the embedding. Our main area of concentration is to obtain the embedding for the provided input captions.
There are four functions used in this pipeline to extract the vectors of captions:
– loadGloveModel( ) – This function loads a pre-trained word embedding dictionary of 40000 words with 300 sized vectors each.
– Cap_tokenize(captions) – This function splits the sentences into tokens (words), removes punctuations, single letters, and finally joins them back as sentences.
– Text2seq (tokenized_captions) – This function converts captions into sequences of integers using Tensorflow functions like pad_sequences and text_to_sequences. The max vocabulary size is fixed as 4500 and the max length of any sequence is set as 30.
1. First, create a Tokenizer object with a vocabulary size of 4500.
2. The object is then trained on cleaned captions that return a word dictionary with an index based on the frequency of word occurrence in descending order.
3. Now, the captions are converted to integer sequences.
4. Use pad_sequences to have a max of 30 sequences in one row.
5. Create an embedding matrix of size (Vocab_size, 300 ), where 300 is the word vector dimension.
This function returns the word dictionary, tokenizer object, embedding matrix, and caption converted as sequences.

Below is the function Loading the Glove 300D model:

Below are the functions for text preprocessing and conversion of text to sequences:

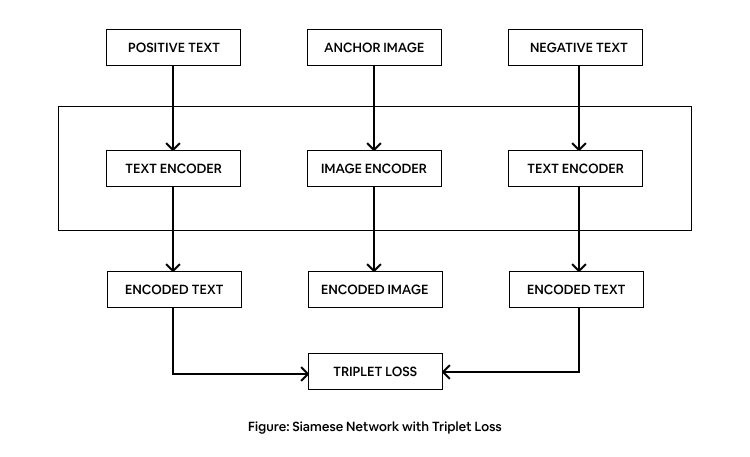
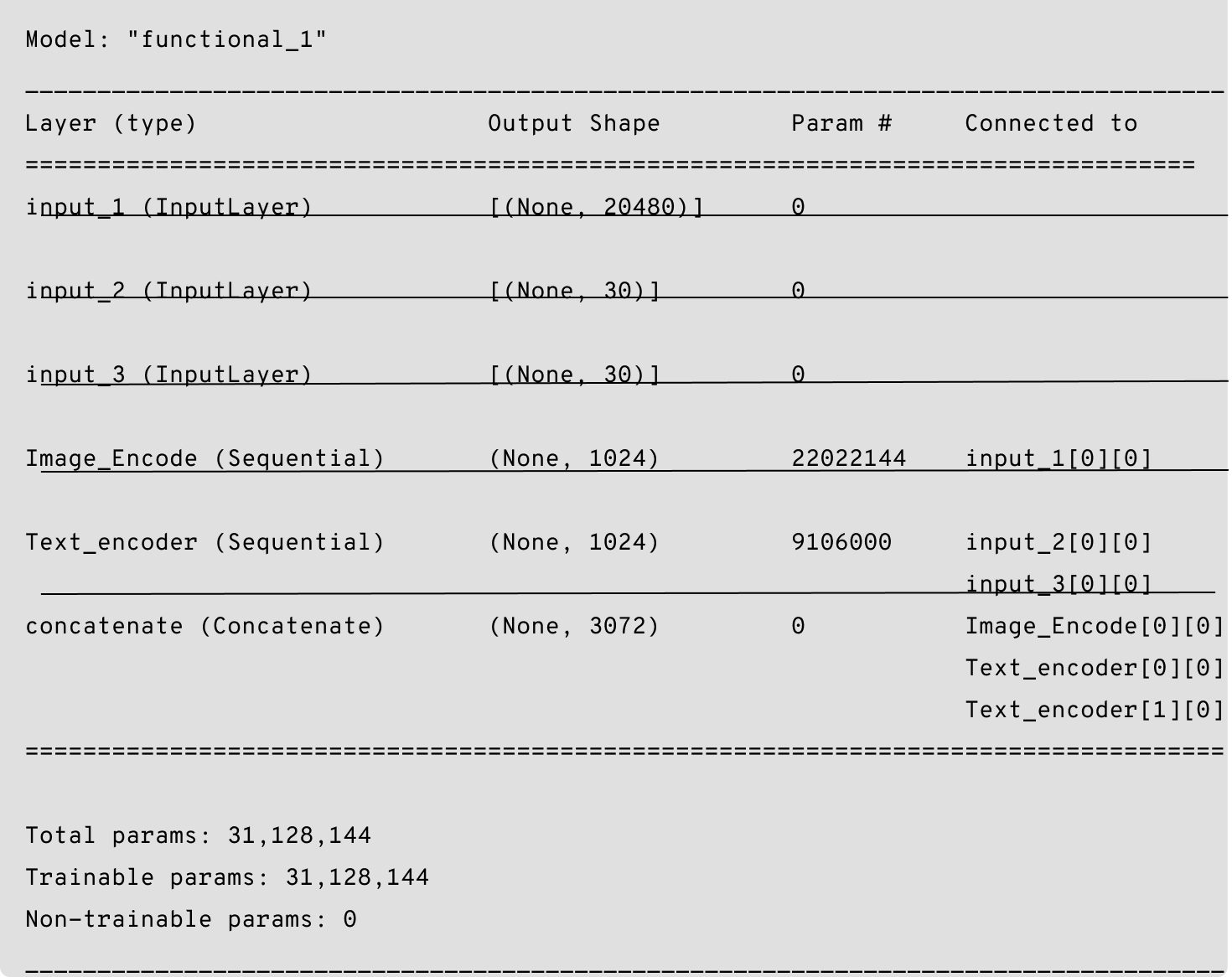
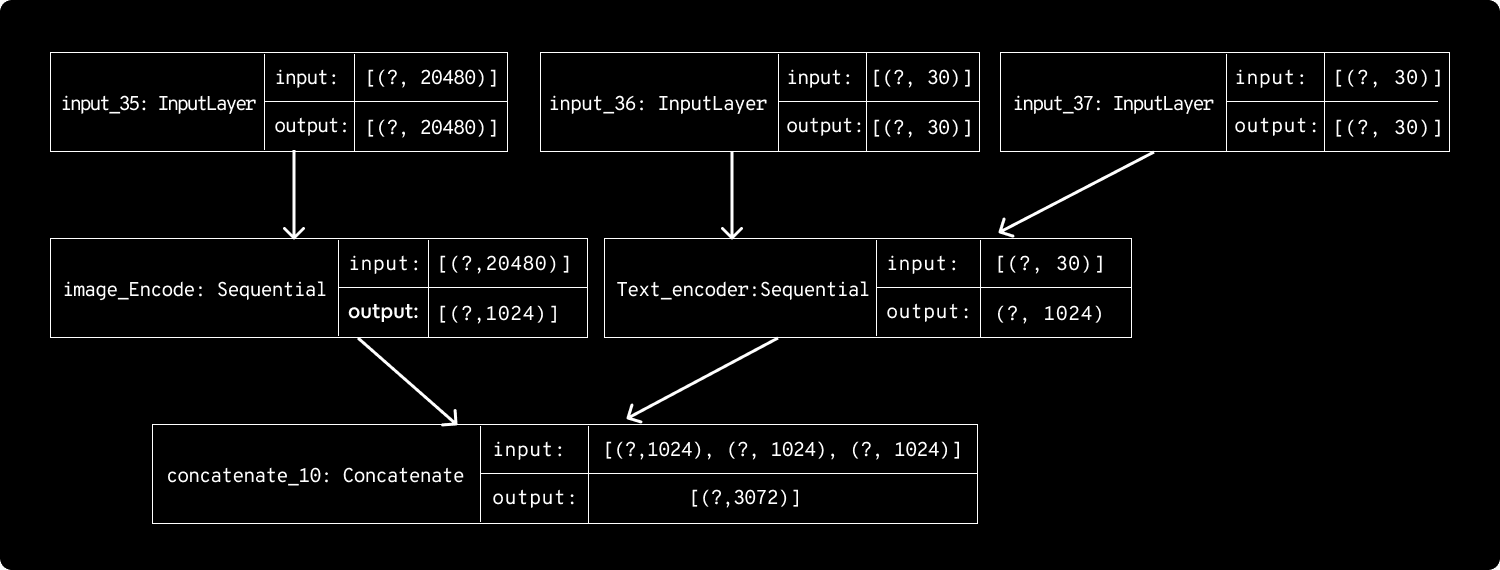
Building Siamese network with triplet loss (similarity network)
A Siamese network, an artificial neural network, computes comparable output vectors by using the same weight while working sequentially in two different input vectors. Learning in such a kind of a twin network can be done by considering the triplet/contrastive loss function.
The similarity network with triplet loss accepts three branches of input – consisting of an anchor image, a negative caption, and a positive caption in the embedded form. This network is an improvised version of a contrastive loss model, where if given a single input, it learns about the correct pair of image and text as well as learns which of the image-text pairs are not suited.
Each branch will be passed through a series of transformations (applied by fully connected layers separated by rectified linear unit non-linearities) which will output the similarity scores based on the Euclidean distance metric, after the conversion to modality robust features. The training objective is to minimize the triplet loss function that applies a margin-based penalty to an incorrect caption when it gets ranked higher than the correct one describing the anchor image similarly for the given positive caption, i.e., the image gets ranked higher than the unrelated images.
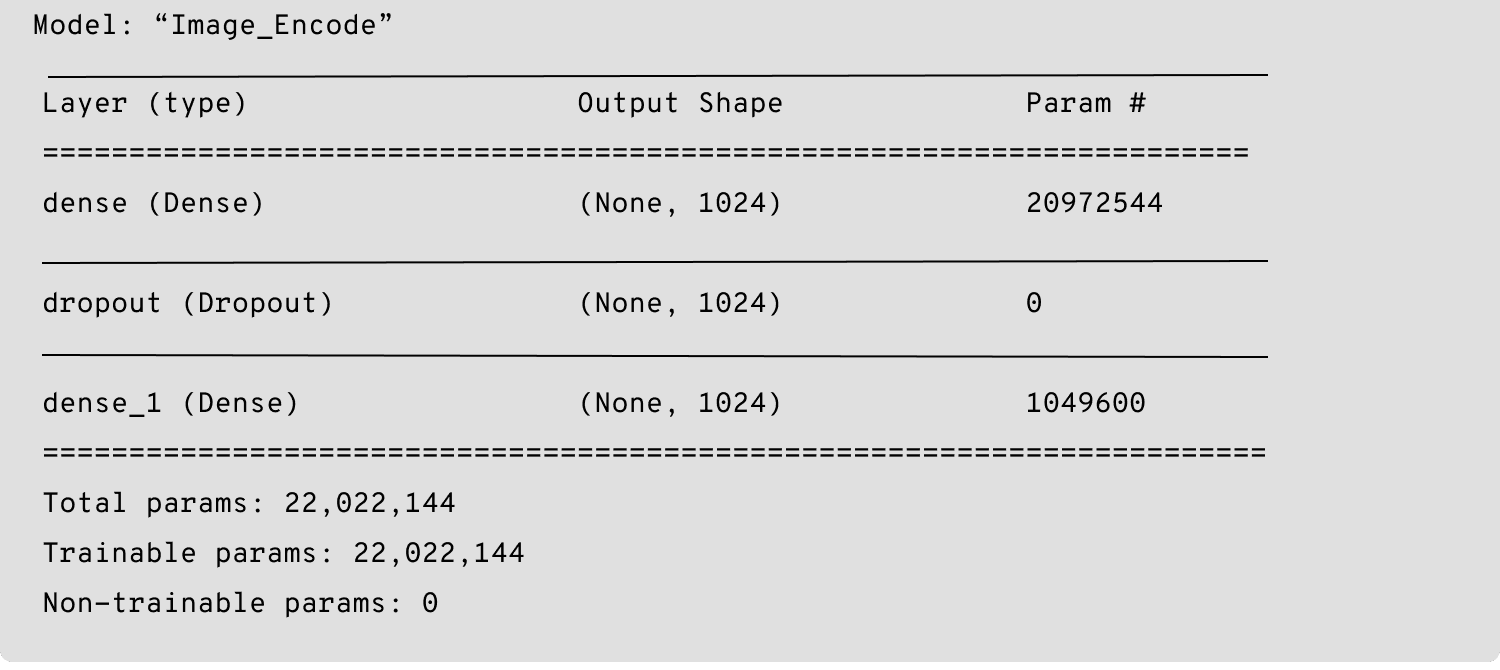
Below is the model for the image encoder:
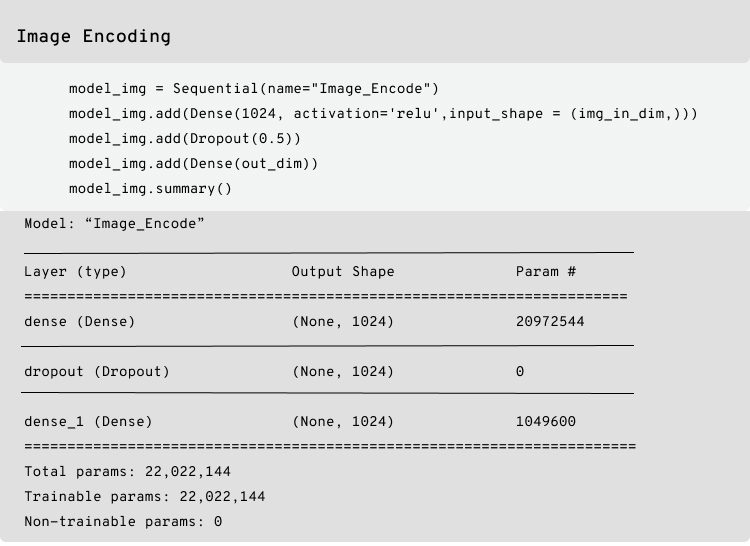
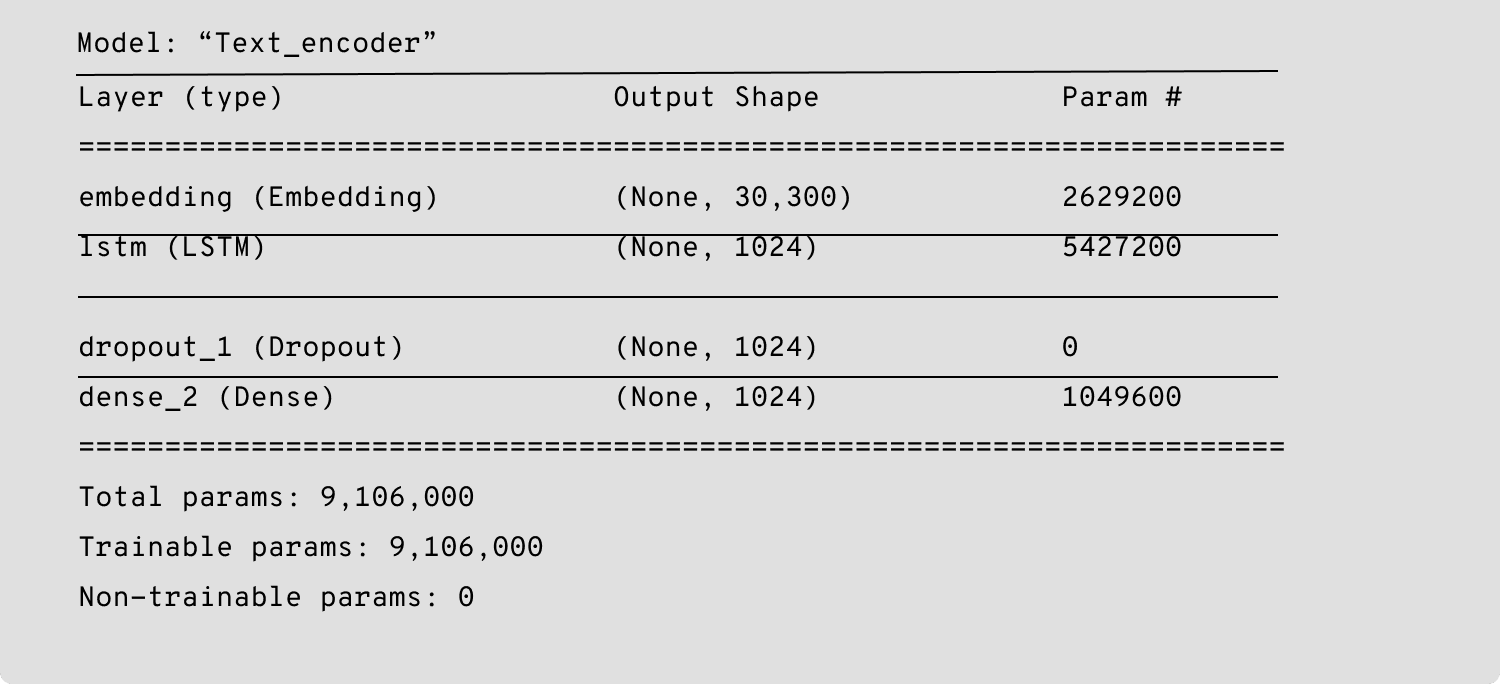
Below is the model for text encoder:
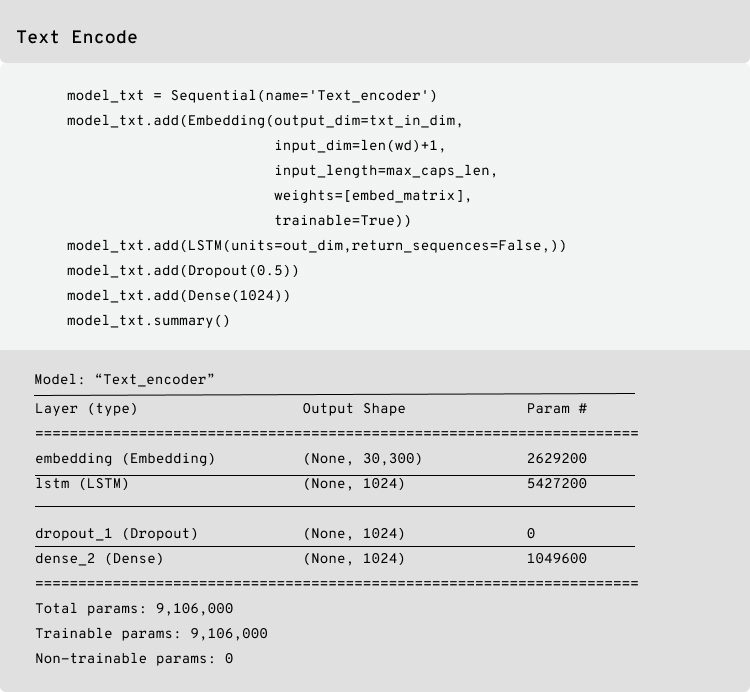
Below is the Siamese model:

Triplet batching and Triplet loss
Given the anchor image “a”. Let p and n be the matching positive caption and the non-matching negative caption. We will calculate the euclidean distance between D1 (a, p) and D2 (a, n). We want the D1 value to be smaller than the distance value D2 and according to the definition of triplet loss, each negative caption “n” should be enforced with a margin of “m” which is called to be neighborhood updation. Based on the definition of triplet loss there are various options of selecting the triplets namely:
– Easy triplets
– Semi-hard triplets
– Hard triplets
An easy triplet has a loss of zero because D(a, p) + m will be less than D(a, n). Whereas, hard triplets are the ones in which the negative caption is closer to the anchor image than the positive caption because D(a, n) is less than D(a, P). Semi-hard triplets are the ones where the negative caption is not closer to the anchor image than the positive caption – which still has a positive loss associated with it because D(a, p) is less than D (a, n) which is less than D(a, p) + m.
The ultimate goal is – given a caption, a pool of images, and given a K value for recall, the model should be able to retrieve the most relevant images with lower loss.
Below is the code snippet for Triplet batching function (Easy triplets) and Triplet loss function-



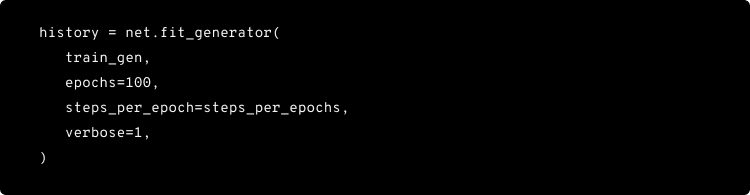
Training the Similarity network
Now that we have built our siamese network and triplet dataset, it is time to train our model. The data consist of 8091 images with 5 captions per image and out of which, 6091 images and their captions are used for training.
The training parameters are:

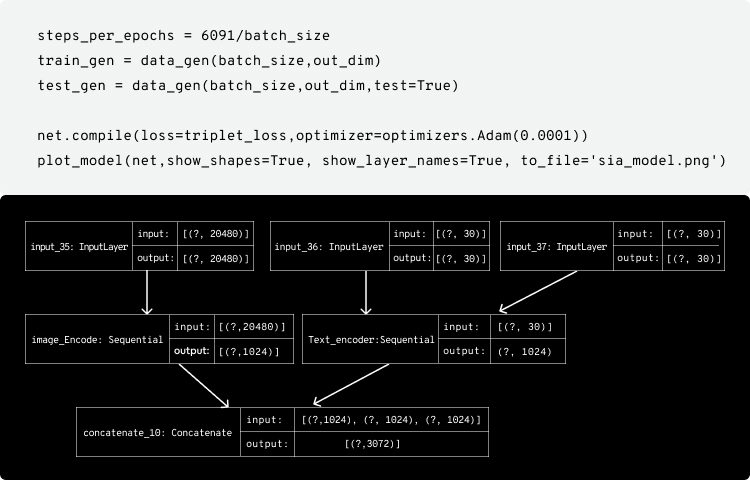
Following is the training loss plot :
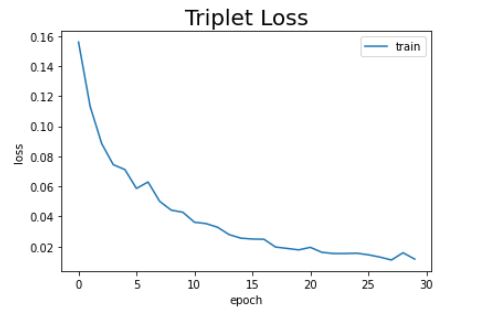
Evaluation
As our model is now trained to understand the semantic similarity between an image and its corresponding captions, it is time to evaluate the model with test cases. For that, it is necessary to build a function user_input_text_embed( ) :
– The user can give any text query. The text is converted to a tokenized integer sequence. For this we use the same Tokenizer object we trained on train captions.
– The tokenized sequence is given to text_encode_model to predict its text embedding.

These are some text inputs –

Cosine Similarity Function:
We are now using cosine similarity to find the K-nearest image embeddings to the given text embedding.

Let us keep K =10, which means to output the top 10 images for a given text query.

Candidate index contains the index of 10 images :
Example: array([7778, 5830, 6500, 6534, 2893, 6290, 6354, 3239, 6948, 7762])
Find the corresponding images using the indices:

Plotting Top K images in a grid:


Conclusion
We have given a custom query to which we were able to retrieve the top 10 ranked images corresponding to the query entered. To analyze the performance, we have shown, both, success and failure scenarios. From the images above, we can consider Text Query 1 as a successful scenario and Text Query 2 as a failure scenario because, for Text Query 2, only one image that corresponds to the context has been retrieved. All other images are of different contexts. This tells that the proposed model doesn’t work for all cases and contexts. For better contextual mapping of image and text, attribute or instance-based mapping can be built, where we localize each object instance in an image to the matching context of a query.
Image retrieval techniques, text-based and content-based, are gaining popularity with the abundant growth of visual information in large digital databases in recent years. They also have wide applicability in areas such as medical, remote sensing, forensic, security, ecommerce, multimedia, etc. as they have become a very active research area for database management and Computer Vision.
Have something to discuss with us about this? Feel free to contact us.


The plot of 4 random images with corresponding captions are shown below:
Get image embedding
Extraction of visual features is done by using a pre-trained model on ImageNet. ImageNet pretraining is an auxiliary task in Computer Vision problems. It is formally a project aimed at manually labeling and categorizing images into almost 22,000 separate object categories for the purpose of Computer Vision research. The state-of-the-art pre-trained networks included in the Keras core library demonstrate a strong ability to generalize images in real-life scenarios via transfer learning, such as feature extraction and fine-tuning.
There are various pre-trained models like VGG-19, RESNET, etc. Here we are using ResNet 50 for getting the image vectors. We need only the embedding vector, so we will not be using the entire network. Instead, we will use it until the “conv5_block3_3_conv” layer finally gives a 2048 sized embedding.
Below is the code snippet for extracting the image embeddings.
In order to further optimize the performance of the model, instead of loading the entire image into the embedding model let us try and create mini-batches that yield a pool of image sets. Online preprocessing is applied on these mini-batches by converting the image into an n-dimensional array of pixel values, which are further normalized and passed into the CNN model that we considered from ResNet50 for prediction. The resultant output is the image embedding for the pool of images generated by the mini-batch creator. Online batch creation is the idea of yielding the preprocessed images on the fly based on the batch size mentioned.
Get text embedding
For text embedding, individual words are represented as real-valued vectors in a predefined vector space where each word is mapped to one vector. The text embedding technique is often merged into the field of Deep Learning as the vector values are learned in a way that resembles a neural network. The distributed representation, based on the usage of words, captures their meaning by allowing words used in similar ways to result in having similar representations.
There are various pre-trained models, like Glove, SkipThoughts, etc, to get text embedding performed. The model we are considering is the Glove pre-trained model that derives the relationship between the words. It considers the global statistics-GloVe 300-dimensional vectors trained on the 42B token common crawl corpus.
The idea is to create a representation of words that capture the meanings, semantic relationships, and the contexts that they are used in. This will help us to achieve transfer learning. Transfer learning could be either about the words or about the embedding. Our main area of concentration is to obtain the embedding for the provided input captions.
There are four functions used in this pipeline to extract the vectors of captions:
– loadGloveModel( ) – This function loads a pre-trained word embedding dictionary of 40000 words with 300 sized vectors each.
– Cap_tokenize(captions) – This function splits the sentences into tokens (words), removes punctuations, single letters, and finally joins them back as sentences.
– Text2seq (tokenized_captions) – This function converts captions into sequences of integers using Tensorflow functions like pad_sequences and text_to_sequences. The max vocabulary size is fixed as 4500 and the max length of any sequence is set as 30.
1. First, create a Tokenizer object with a vocabulary size of 4500.
2. The object is then trained on cleaned captions that return a word dictionary with an index based on the frequency of word occurrence in descending order.
3. Now, the captions are converted to integer sequences.
4. Use pad_sequences to have a max of 30 sequences in one row.
5. Create an embedding matrix of size (Vocab_size, 300 ), where 300 is the word vector dimension.
This function returns the word dictionary, tokenizer object, embedding matrix, and caption converted as sequences.


Building Siamese network with triplet loss (similarity network)
A Siamese network, an artificial neural network, computes comparable output vectors by using the same weight while working sequentially in two different input vectors. Learning in such a kind of a twin network can be done by considering the triplet/contrastive loss function.
The similarity network with triplet loss accepts three branches of input – consisting of an anchor image, a negative caption, and a positive caption in the embedded form. This network is an improvised version of a contrastive loss model, where if given a single input, it learns about the correct pair of image and text as well as learns which of the image-text pairs are not suited.
Each branch will be passed through a series of transformations (applied by fully connected layers separated by rectified linear unit non-linearities) which will output the similarity scores based on the Euclidean distance metric, after the conversion to modality robust features. The training objective is to minimize the triplet loss function that applies a margin-based penalty to an incorrect caption when it gets ranked higher than the correct one describing the anchor image similarly for the given positive caption, i.e., the image gets ranked higher than the unrelated images.
Below is the model for the image encoder:
Image Encoding
Following is the training loss plot :
Evaluation
As our model is now trained to understand the semantic similarity between an image and its corresponding captions, it is time to evaluate the model with test cases. For that, it is necessary to build a function user_input_text_embed( ) :
– The user can give any text query. The text is converted to a tokenized integer sequence. For this we use the same Tokenizer object we trained on train captions.
– The tokenized sequence is given to text_encode_model to predict its text embedding.
Conclusion
We have given a custom query to which we were able to retrieve the top 10 ranked images corresponding to the query entered. To analyze the performance, we have shown, both, success and failure scenarios. From the images above, we can consider Text Query 1 as a successful scenario and Text Query 2 as a failure scenario because, for Text Query 2, only one image that corresponds to the context has been retrieved. All other images are of different contexts. This tells that the proposed model doesn’t work for all cases and contexts. For better contextual mapping of image and text, attribute or instance-based mapping can be built, where we localize each object instance in an image to the matching context of a query.
Image retrieval techniques, text-based and content-based, are gaining popularity with the abundant growth of visual information in large digital databases in recent years. They also have wide applicability in areas such as medical, remote sensing, forensic, security, ecommerce, multimedia, etc. as they have become a very active research area for database management and Computer Vision.
Have something to discuss with us about this? Feel free to contact us.
