May 3, 2021Artificial Intelligence , Machine Learning
Day by day the number of machine learning models is increasing at a pace. With this increasing rate, it is hard for beginners to choose an effective model to perform Natural Language Understanding (NLU) and Natural Language Generation (NLG) mechanisms. Researchers across the globe are working around the clock to achieve more progress in artificial intelligence to build agile and intuitive sequence-to-sequence learning models. And in recent times transformers are one such model which gained more prominence in the field of machine learning to perform speech-to-text activities.
The wide availability of other sequence-to-sequence learning models like RNNs, LSTMs, and GRU always raises a challenge for beginners when they think about transformers. And it is important to a beginner to have basic knowledge of these models before they get to know more about transformers. If you still struggle why not RNNs, LSTMs, and GRUs, here we listed a few important points that can help you out.
– RNNs process the data sequentially i.e., one word at a time as an input to the model and one word as an output. This takes more time to process the input.
– Using longer text sequences as input to RNNs makes the model learn only the recent text in the input because of Vanishing Gradient. As a result, the model fails to learn longer sequences. Usage of Truncated BTT(ex: using a window of the last 10 timestamps only) also makes the model too slow than before and still fails to handle longer text.
– Usage of keep/delete/update gates in LSTM makes sequence processing better than RNNs. But even LSTMs are also too slow than RNNs as they involve heavy computation mechanisms inside gates.
Why Transformers?
Before learning more about transformers here is a brief explanation about sequence-to-sequence learning. The paper “Attention Is All You Need” describes more transformers and sequence-to-sequence architecture.
Seq2Seq is a neural net that transforms a given sequence of elements as the sequence of words in a sentence into another sequence. And these models are especially good at translation. This model can seamlessly translate the words from one language into a sequence of different words in other languages. Seq2seq models’ architecture is a framework of an encoder and decoder. The encoder takes the input sequence and maps it into a higher dimensional vector and thereafter the abstract vector is fed into the decoder which finally maps the output sequence which can be other languages, symbols, a copy of the input, etc.
Transformers use positional encoding, multi-head attention, and normalization state-of-art strategies to decode a sequence for performing sequence processing tasks. Transformers take the advantage of parallel computing to operate sequence processing tasks, which reduces the computation time and delivers results at a faster speed. Whereas other models of NLP like RNNs, LTMs, and GRUs take one input at a single timestamp and make no use of parallel computing available through GPUs.
Transformer Architecture
Transformer architecture is first introduced in the paper “Attention is all you need” from Ashish Vaswani and Nikki Parmer along with others. As said earlier every model that performs seq2seq analysis has an encoder and decoder and the same applies to a transformers architecture. And below we listed a pictographic representation of transformer architecture:
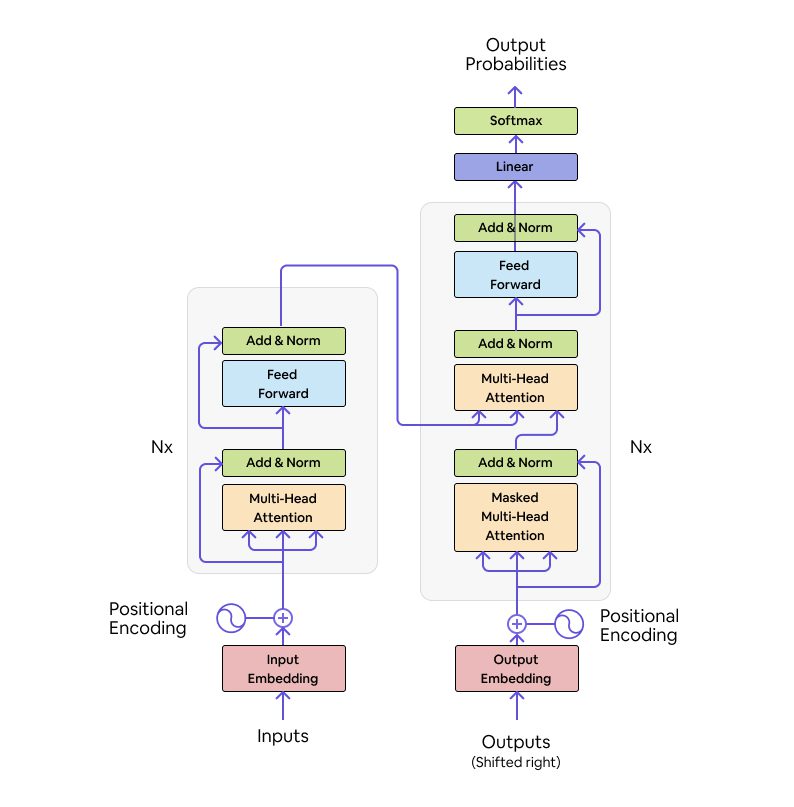
Source: ARXIV
Encoder-Decoder: Transformer architecture is a combination of encoders and decoders as shown below. There can be multiple encoders and decoders stacked on top of each other. In this paper, both encoder and decoder are composed of a stack of 6 identical layers as N=6.
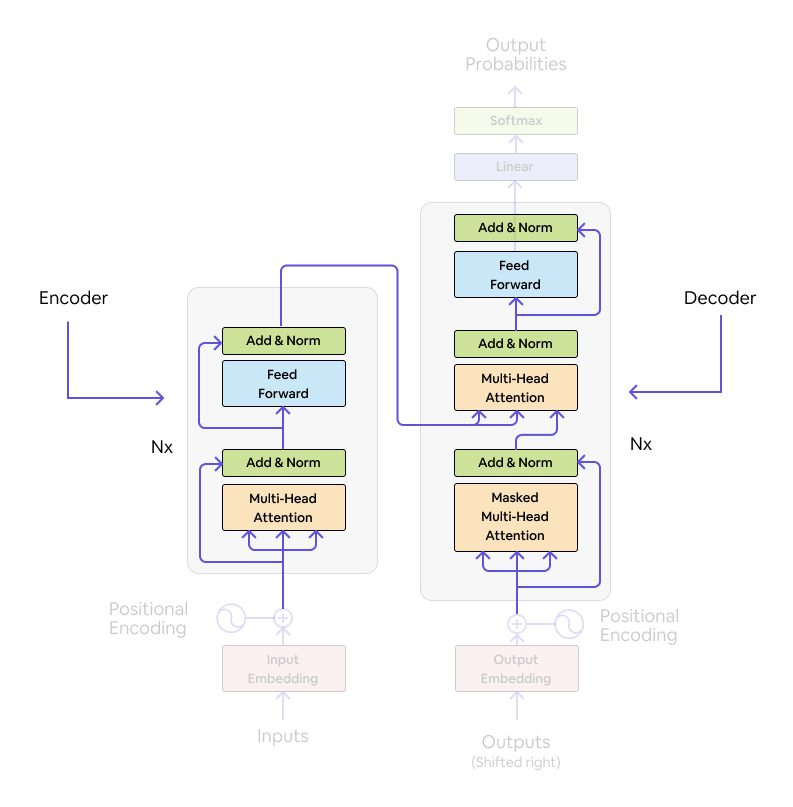
Source: Analytics Vidhya
Encoder: Each layer of those N=6 identical layers has 2 sub-layers. The first is a multi-head self-attention mechanism. The second is a simple, position-wise fully connected feed-forward network. Each sub-layer adopts a residual connection and a layer normalization. All the sub-layers output data of the same dimension model=512.
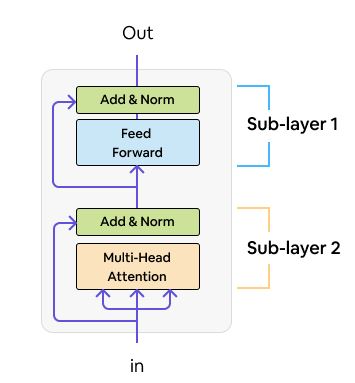
Encoder in Transformer
Decoder: The Decoder has 3 sublayers in it – masked multi-head attention, multi-head attention and a Feedforward layer. All these 3 sublayers have added norm layers in them. A Softmax and Linear layer is added at the end of the decoder, where the number of neurons in linear layers is equal to the number of words in the output sentence.
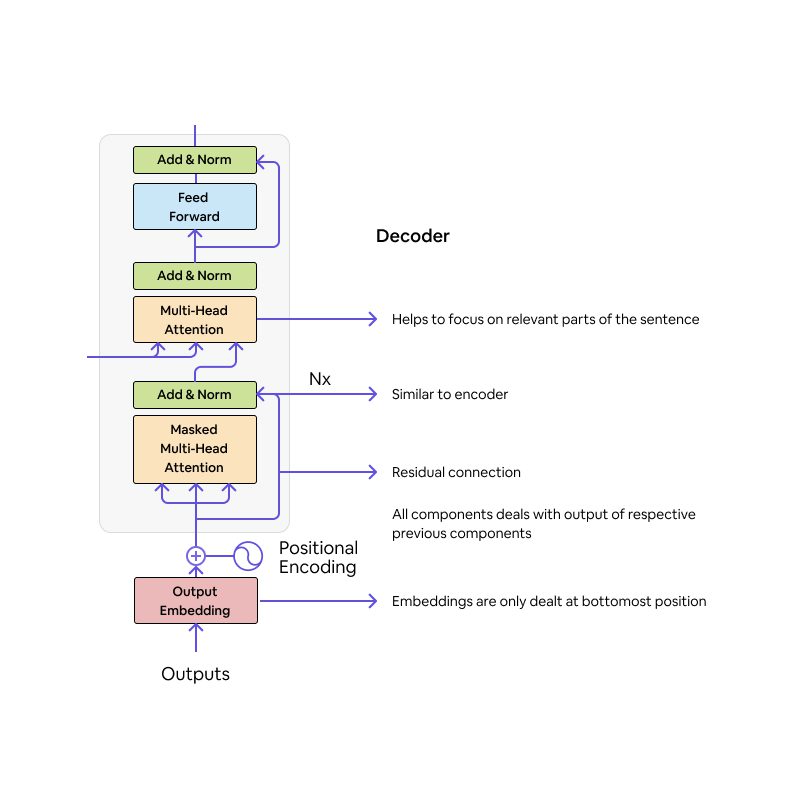 Positional Encoding: Sentences are passed in sequence to preserve the order. Once such sequences are converted to tokens, they do not have any order now. Hence we add positional encoding. Use of positional encoding after input embedding and output embedding helps to catch the context of the words in different sentences in input that we give to the model.
Positional Encoding: Sentences are passed in sequence to preserve the order. Once such sequences are converted to tokens, they do not have any order now. Hence we add positional encoding. Use of positional encoding after input embedding and output embedding helps to catch the context of the words in different sentences in input that we give to the model.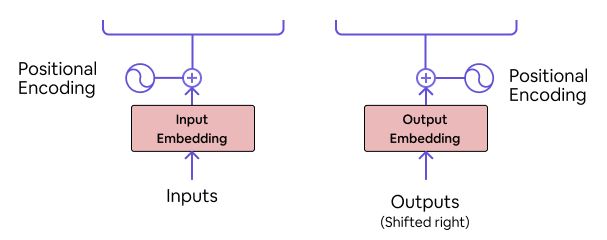
Multi-Head Attention: The multi-head attention layer in both the encoder and the decoder comes with little complex computations. It uses scaled dot product attention as its core.
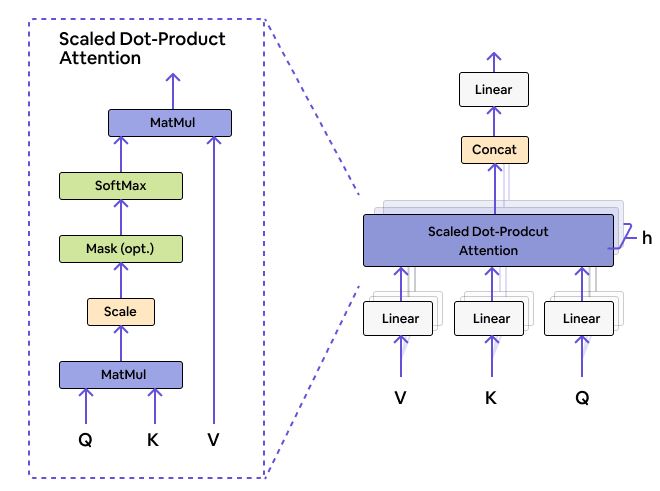
Source: Github
Usage of attention in Transformers is to enable the relationship of a word with all the other words in the sequence. In other words, it finds the correlations of the different words in the sequence. This helps the model to understand what each word in a sequence refers to.

The above image is an example of a transformer that uses an attention mechanism, the model can understand that the word it refers to the word street with more weight than the word animal. We humans easily understand the context using their semantics. The transformer uses an attention mechanism for the same.
Masked Multi-Head attention: Masked Multi-head attention masks the next words in the sentence to prevent the model from looking at the future word so that model has to predict the next word without looking at the original text word in the sequence.
The downsides of this architecture are:
– The transformer is undoubtedly the most advanced application over the RNN based seq2seq models. But the attentions can only deal with fixed-length text strings. The entire text data has to be split into a defined number of segments before being fed into an input system.
– Transformer architecture calculates the output for the time-stamp from the entire history of the data instead of only inputs and current hidden-state, which makes this model less efficient.
– If the input has a temporal/spatial relationship (like; text), some positional encoding must be added to eliminate model in-accuracy, or else the model can effectively see a bag of words.
Transformer Architecture Flow:
After training the model, let’s say you want to translate sentences from English to German. Input text sequence from English is given as input to the encoder block.
– Text gets converted to embeddings.
– Positional encodings are applied on embeddings to attach the position of each word in a sequence to maintain order and context. They output positional vectors.
– These vectors are given to the encoder block which implements multi-head attention and feed-forward layer to learn where to keep attention in a text when a sequence is given for different words in the sequence.
– These vectors with position tagged and attention marked goes to the second sub-layer of a decoder which is nothing but another multi-head attention layer.
The output language as we discussed ‘German’ given as input to the decoder block;
– This German target-language text is also converted to embeddings and given to positional encodings.
-After applying positional encoding, you will have vectors with positions tagged to maintain order and context as happened for input language in English.
– These embeddings are passed to masked multi-head attention which is the first sublayer in the decoder to mask the output text to prevent the model from seeing the original future word.
– These vectors along with output from the encoder are given to the second sublayer in the decoder which is a multi-head attention layer.
– In the above step, both the original language text and target text pairs go to the model to learn the supposed language word for the original language world. The model sees both language versions of a single word here. They are mostly mapped to exact words as order and context are maintained.
– Finally, these combinations go to linear and softmax to generate the most probable prediction of the input text that we gave.
Code for language translation:
For demonstration, we are going to learn the use of transformers to translate English to German from Huggingface transformer library using their pretrained models.
Install the library using the below commands
Transformers For Tomorrow
Today, mostly transformers are being used in neural machine translation frameworks as they have proven to be the best in this space. As the research continues the application of transformer models scales to other vertices. A transformer model can seamlessly perform almost any or NLP tasks. One can leverage these applications for language modeling, translation, or classification. And the transformers model does the above-mentioned tasks rapidly by removing the sequential nature of the problem.

The above image shows how a transformer model looks for translation. Here in the reference image the model takes an English sentence as an input and returns a German sentence. Everything depends on the final output layer for the network mechanism, and the basic structure for the transformer remains the same. For a classification problem, the class probability is added using an appropriate output layer for effective output.
Transformers are pretty versatile and can be used in a variety of NLP tasks, such as; Machine Translation, Text Summarization, Speech Recognition, Question-Answering systems, and so on.
For any further information or discussions, feel free to contact us.
Day by day the number of machine learning models is increasing at a pace. With this increasing rate, it is hard for beginners to choose an effective model to perform Natural Language Understanding (NLU) and Natural Language Generation (NLG) mechanisms. Researchers across the globe are working around the clock to achieve more progress in artificial intelligence to build agile and intuitive sequence-to-sequence learning models. And in recent times transformers are one such model which gained more prominence in the field of machine learning to perform speech-to-text activities.
The wide availability of other sequence-to-sequence learning models like RNNs, LSTMs, and GRU always raises a challenge for beginners when they think about transformers. And it is important to a beginner to have basic knowledge of these models before they get to know more about transformers. If you still struggle why not RNNs, LSTMs, and GRUs, here we listed a few important points that can help you out.
– RNNs process the data sequentially i.e., one word at a time as an input to the model and one word as an output. This takes more time to process the input.
– Using longer text sequences as input to RNNs makes the model learn only the recent text in the input because of Vanishing Gradient. As a result, the model fails to learn longer sequences. Usage of Truncated BTT(ex: using a window of the last 10 timestamps only) also makes the model too slow than before and still fails to handle longer text.
– Usage of keep/delete/update gates in LSTM makes sequence processing better than RNNs. But even LSTMs are also too slow than RNNs as they involve heavy computation mechanisms inside gates.
Why Transformers?
Before learning more about transformers here is a brief explanation about sequence-to-sequence learning. The paper “Attention Is All You Need” describes more transformers and sequence-to-sequence architecture.
Seq2Seq is a neural net that transforms a given sequence of elements as the sequence of words in a sentence into another sequence. And these models are especially good at translation. This model can seamlessly translate the words from one language into a sequence of different words in other languages. Seq2seq models’ architecture is a framework of an encoder and decoder. The encoder takes the input sequence and maps it into a higher dimensional vector and thereafter the abstract vector is fed into the decoder which finally maps the output sequence which can be other languages, symbols, a copy of the input, etc.
Transformers use positional encoding, multi-head attention, and normalization state-of-art strategies to decode a sequence for performing sequence processing tasks. Transformers take the advantage of parallel computing to operate sequence processing tasks, which reduces the computation time and delivers results at a faster speed. Whereas other models of NLP like RNNs, LTMs, and GRUs take one input at a single timestamp and make no use of parallel computing available through GPUs.
Transformer Architecture
Transformer architecture is first introduced in the paper “Attention is all you need” from Ashish Vaswani and Nikki Parmer along with others. As said earlier every model that performs seq2seq analysis has an encoder and decoder and the same applies to a transformers architecture. And below we listed a pictographic representation of transformer architecture:
Source: ARXIV
Encoder-Decoder: Transformer architecture is a combination of encoders and decoders as shown below. There can be multiple encoders and decoders stacked on top of each other. In this paper, both encoder and decoder are composed of a stack of 6 identical layers as N=6.
Source: Analytics Vidhya
Encoder: Each layer of those N=6 identical layers has 2 sub-layers. The first is a multi-head self-attention mechanism. The second is a simple, position-wise fully connected feed-forward network. Each sub-layer adopts a residual connection and a layer normalization. All the sub-layers output data of the same dimension model=512.
Encoder in Transformer
Decoder: The Decoder has 3 sublayers in it – masked multi-head attention, multi-head attention and a Feedforward layer. All these 3 sublayers have added norm layers in them. A Softmax and Linear layer is added at the end of the decoder, where the number of neurons in linear layers is equal to the number of words in the output sentence.
Positional Encoding: Sentences are passed in sequence to preserve the order. Once such sequences are converted to tokens, they do not have any order now. Hence we add positional encoding. Use of positional encoding after input embedding and output embedding helps to catch the context of the words in different sentences in input that we give to the model.
Multi-Head Attention: The multi-head attention layer in both the encoder and the decoder comes with little complex computations. It uses scaled dot product attention as its core.
Source: Github
Usage of attention in Transformers is to enable the relationship of a word with all the other words in the sequence. In other words, it finds the correlations of the different words in the sequence. This helps the model to understand what each word in a sequence refers to.
The above image is an example of a transformer that uses an attention mechanism, the model can understand that the word it refers to the word street with more weight than the word animal. We humans easily understand the context using their semantics. The transformer uses an attention mechanism for the same.
Masked Multi-Head attention: Masked Multi-head attention masks the next words in the sentence to prevent the model from looking at the future word so that model has to predict the next word without looking at the original text word in the sequence.
The downsides of this architecture are:
– The transformer is undoubtedly the most advanced application over the RNN based seq2seq models. But the attentions can only deal with fixed-length text strings. The entire text data has to be split into a defined number of segments before being fed into an input system.
– Transformer architecture calculates the output for the time-stamp from the entire history of the data instead of only inputs and current hidden-state, which makes this model less efficient.
– If the input has a temporal/spatial relationship (like; text), some positional encoding must be added to eliminate model in-accuracy, or else the model can effectively see a bag of words.
Transformer Architecture Flow:
After training the model, let’s say you want to translate sentences from English to German. Input text sequence from English is given as input to the encoder block.
– Text gets converted to embeddings.
– Positional encodings are applied on embeddings to attach the position of each word in a sequence to maintain order and context. They output positional vectors.
– These vectors are given to the encoder block which implements multi-head attention and feed-forward layer to learn where to keep attention in a text when a sequence is given for different words in the sequence.
– These vectors with position tagged and attention marked goes to the second sub-layer of a decoder which is nothing but another multi-head attention layer.
The output language as we discussed ‘German’ given as input to the decoder block;
– This German target-language text is also converted to embeddings and given to positional encodings.
-After applying positional encoding, you will have vectors with positions tagged to maintain order and context as happened for input language in English.
– These embeddings are passed to masked multi-head attention which is the first sublayer in the decoder to mask the output text to prevent the model from seeing the original future word.
– These vectors along with output from the encoder are given to the second sublayer in the decoder which is a multi-head attention layer.
– In the above step, both the original language text and target text pairs go to the model to learn the supposed language word for the original language world. The model sees both language versions of a single word here. They are mostly mapped to exact words as order and context are maintained.
– Finally, these combinations go to linear and softmax to generate the most probable prediction of the input text that we gave.
Code for language translation:
For demonstration, we are going to learn the use of transformers to translate English to German from Huggingface transformer library using their pretrained models.
Install the library using the below commands


Our output for the entered English sentence when translated to German would be

Transformers For Tomorrow
Today, mostly transformers are being used in neural machine translation frameworks as they have proven to be the best in this space. As the research continues the application of transformer models scales to other vertices. A transformer model can seamlessly perform almost any or NLP tasks. One can leverage these applications for language modeling, translation, or classification. And the transformers model does the above-mentioned tasks rapidly by removing the sequential nature of the problem.
The above image shows how a transformer model looks for translation. Here in the reference image the model takes an English sentence as an input and returns a German sentence. Everything depends on the final output layer for the network mechanism, and the basic structure for the transformer remains the same. For a classification problem, the class probability is added using an appropriate output layer for effective output.
Transformers are pretty versatile and can be used in a variety of NLP tasks, such as; Machine Translation, Text Summarization, Speech Recognition, Question-Answering systems, and so on.
For any further information or discussions, feel free to contact us.
