November 5, 2021Artificial Intelligence , Computer Vision , Machine Learning
Image annotation is one of the vital applications of computer vision, which allows the machines a high-level ability to deconstruct digital images or videos and interpret the visual information just like humans. Most of the remarkable applications of AI like self-driving cars, medical imaging, self-flying drones, etc., are only possible through image annotation.
While image annotation is the technique that makes the machine learning models experience visual perception to detect objects in their natural surroundings, it is important to understand the practice of image annotation in AI and machine learning to further explore its applications. In this article, we have discussed a complete guide to understand and integrate image annotation modules for your application.
Image Annotation and Types
Image annotation is the process of labeling the data to make the object in the image recognizable to machines through computer vision applications. It is used to detect, classify, and group the objects in machine learning programming for effective learning of the data.
Image annotation with the help of computer vision-assisted AI is lessening the manual work requirements. Preferably supervised machine learning engineers predetermine the labels, known as classes, and train the image-specific computer vision models. After a successful deployment of a pre-trained model, one determines the predetermined features for the rest of the images in the data set that have not been annotated.
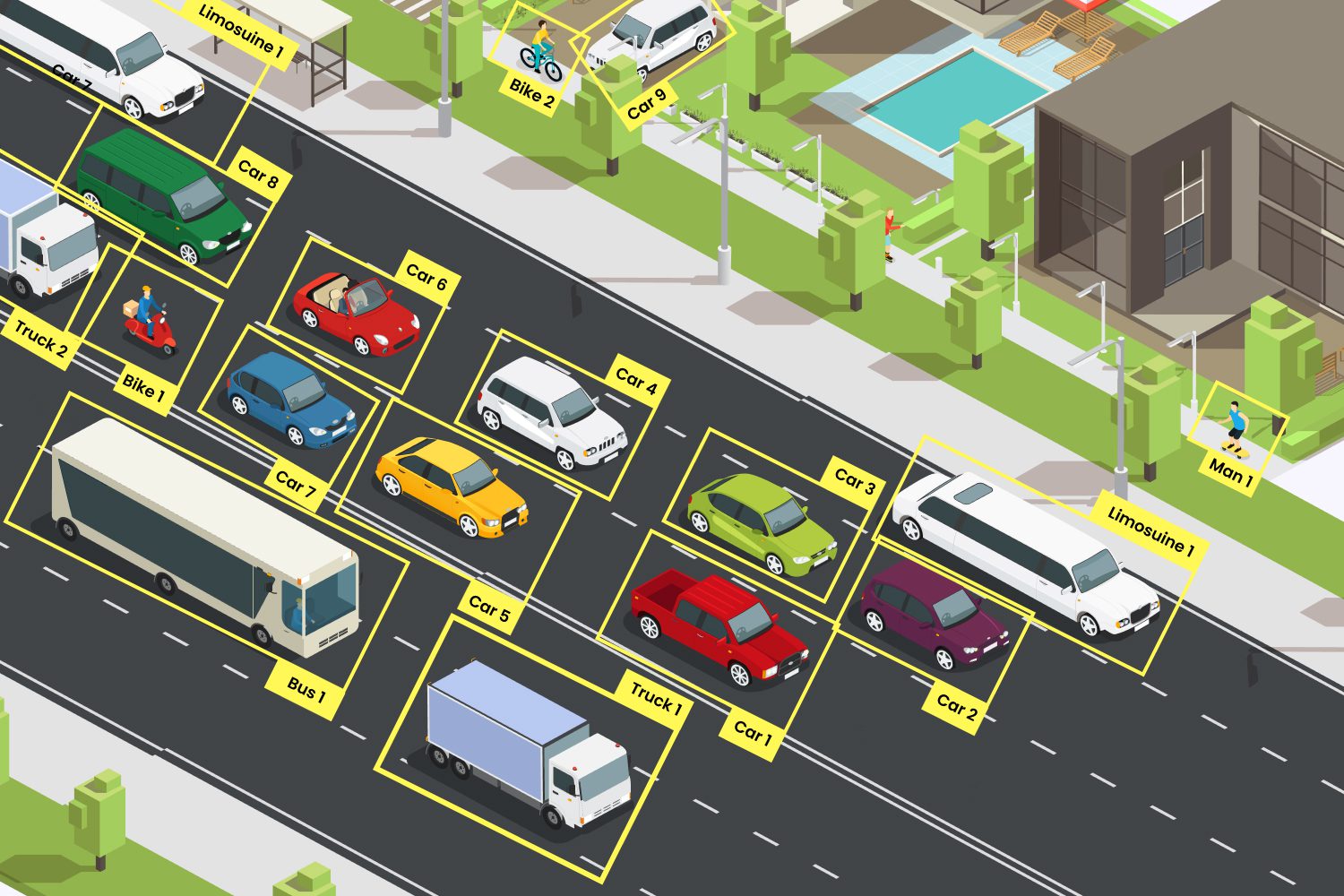
1. Bounding Box Annotation
Bounding box annotation is a method of outlining the object with rectangular or square boxes that can be readable by computer vision models to perform AI and machine learning tasks. These bounding boxes determine the label of each object with a specific color for effective reading. A bounding box will provide the actual identification of an object with the interest specific to the image.
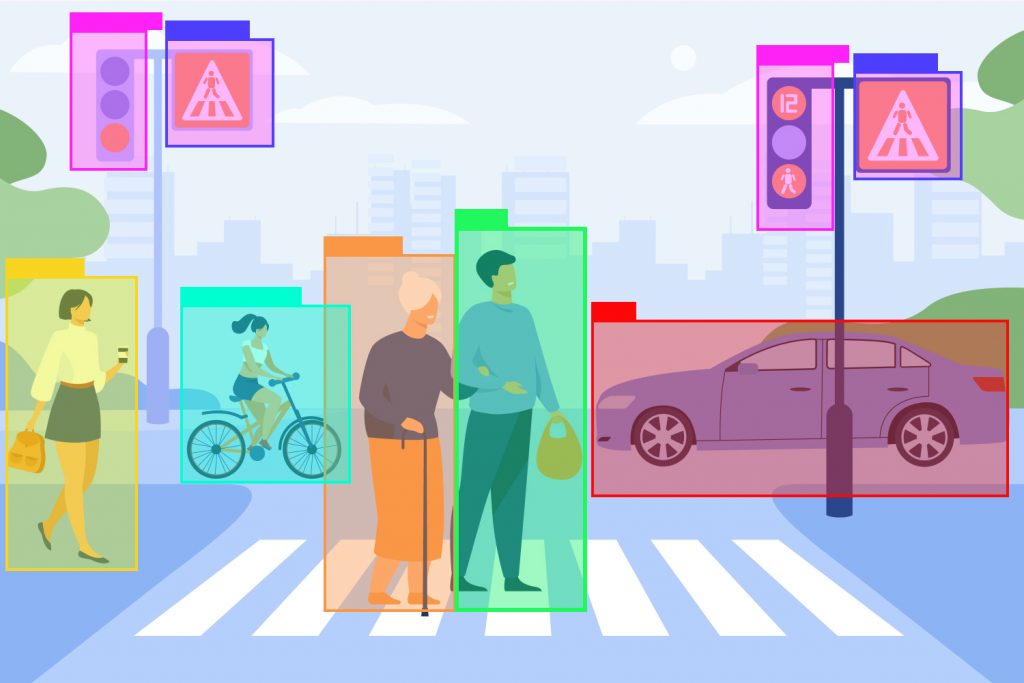
2. 2D & 3D Cuboid Annotation
Cuboid annotation is used to sense the actual dimensions of the objects giving more and specified information to the computer vision models for effective identification. It is most specifically designed to annotate the images for autonomous cars, robotics, and indoor machine operations.
3. Landmark Annotation
Landmark annotation is used to train AI or machine learning models with computer vision algorithms to recognize faces and measure the facial features, expressions, activities, or poses of humans. Landmarking is used for developing highly advanced security systems, surveillance devices, and to perform sports analytics at ease.
4. Polyline Annotation
Polyline annotation is helping the visual perception models to identify the pathways, crossings divided by training a computer vision system with various techniques to identify lines, splines, and polylines. These annotation techniques are effective in the use of self-driving vehicles to identify the street pathways, city crossings, and highways for accurate vehicle movements.
5. Text Annotation
Text annotation is a supervised natural language processing technique to train models to read and understand multilingual text for performing high-quality visualizations. This technique is used to train the robots and automated machines with AI and machine learning for effective and fast learning.
6. Polygon Annotation
Polygon image annotation for computer vision is a technique to identify objects with irregular or asymmetrical shapes within a given image. For instance, the shapes in images like road markings, traffic signs, vehicles dimensions, etc. this technique helps machines to learn and read the specific annotation for effective decision making in a given situation.
7. Semantic & Instance Segmentation Annotation
Annotating images based on semantic segmentation is a computer vision-based AI technique that interprets given digital images by each pixel to define a specific class of objects. Instance segmentation annotation adds detail to imagery by separately labeling objects in the same class.

8. Live Annotation
Live annotation services are offered to train machine learning and AI algorithms with required images and videos to perform annotation in real-time. This technique is usually performed under the guidance of specified professionals with a quick turnaround time.
Video Annotation
Similar to image annotation, a video annotation is used to detect the objects and identify the classes of that object to be machine-readable via a computer vision application.
9. ADAS Annotation
Advanced driver-assistance systems or ADAS annotations is a data annotation technique carried to assist automated and self-driving cars. This method is applied through leveraging various image annotation techniques like bounding boxes, polygons, and semantic segmentation, etc., to make driving monitoring and assistance more efficient and safe.
How does Image Annotation work?
Image annotation is a type of data labeling that is also called tagging, transcribing, or processing. To perform image annotation using supervised machine learning and artificial intelligence algorithms to allow a computer vision model to identify and recognize object classes using the different annotation techniques at scale, below mentioned are a few simple steps.
Step 1: Prepare your image dataset.
Step 2: Give labels to objects in the classes for the models to detect.
Step 3: In every image, draw a box around the object you want the ML model to detect.
Step 4: Select the label for every bounding box you drew.
Step 5: Export the annotations in the most suitable format(COCO JSON, YOLO, etc.)
Why Image Annotation is Important?
With the continuous demand for machine learning and Artificial intelligence applications, the progressive effect to upgrade the computer vision technology implementation into the untapped field of image/video processing, the application of image annotation has become vital practice to improve the performance and efficiency of existing machine learning models. Below listed are a few statements that define the importance of image annotation for machine learning and AI.
– Detect objects of your interests in an image.
– Classify varied objects in the image.
– Recognize different types of classes of objects.
– Improve the performance, efficiency, and accuracy of existing models.
– Image annotation helps machine learning algorithms easily detect and classify objects.
The two most important objectives of image annotation are that it helps machine learning and AI models to label the data sets which help to perform classification and regression of annotated images for a given data much easier and with more accuracy. Secondly, while developing any AI or machine learning model, image annotation is highly used to validate the model’s ability to detect, recognize and classify objects precisely while testing. Hence image annotation has a significant role in applying computer vision for image processing. However, the quality of the machine learning model is completely dependent on training data and the engineers working to train the model.
DeepLobe being a pioneer in machine learning offers data and image annotation services for a wide range of applications for distinct industries with leading techniques of image processing that can assist in integrating pre-trained image annotation models. To know more about other computer vision models or to know more about image annotation techniques contact us.
