
February 8, 2024Uncategorized
Businesses were and are drowning in a sea of unstructured data in the corporate world. Important information gets scattered across documents, making retrieval a daunting task. LLM-based document extraction is a technological marvel that not only rescues businesses from chaos but also opens new doors to unparalleled efficiency.
What is LLM-Based Document Extraction?
LLM (Large Language Models) are built on advanced deep learning techniques and possess the ability to comprehend and generate human-like text. LLM-based document extraction harnesses the power of these models to sift through vast amounts of data, extracting relevant information with unprecedented accuracy.
Technologies Involved
Delving into the workings of LLM-based document extraction unveils a symphony of cutting-edge technologies. Natural Language Processing (NLP) is the guiding force behind the model’s ability to understand and interpret human language. Machine Learning algorithms, especially those based on Transformers, enable the model to learn and adapt, continually improving its performance.
Challenges and Architecture
The journey of LLM-based document extraction has its challenges. As it navigates through complex documents and diverse data formats, challenges such as document variability, domain-specific language, and the need for extensive training data emerge.
The architecture of LLM-based document extraction is a masterpiece in itself. Combining pre-trained language models with domain-specific fine-tuning, the architecture ensures adaptability to various industries and document types. Integration with existing document management systems further streamlines the workflow, making it a seamless addition to any business operation.
The Retrieval Augmented Generation
Large Language Models (LLMs) have revolutionized natural language understanding, yet they grapple with challenges like context preservation, precise information retrieval, and context-aware document summarization. Retrieval Augmented Generation (RAG) emerges as the definitive solution, seamlessly combining retrieval and generation to overcome LLM’s limitations and enhance document extraction capabilities.
Consider the prompt, “Summarize the impact of artificial intelligence on workforce automation.” Without RAG, a traditional LLM may provide a generic summary, potentially missing nuanced details. In contrast, Retrieval Augmented Generation (RAG) seamlessly integrates retrieval and generation, ensuring that the response captures the broad impact and contextualizes specific instances, making the summary richer and more informative.
Response without RAG:
“The impact of artificial intelligence on workforce automation is significant. AI technologies are being increasingly used to automate tasks traditionally performed by humans. This has led to increased efficiency and productivity in various industries.”
Response with RAG:
“The impact of artificial intelligence on workforce automation is a multifaceted phenomenon, evident across industries. In manufacturing, AI-driven robotic systems streamline production processes, enhancing efficiency and reducing labor-intensive tasks. Moreover, in service sectors, AI applications, such as chatbots and virtual assistants, redefine customer interactions, showcasing the transformative influence of AI on diverse aspects of workforce dynamics.”
RAG Architecture for LLMs
The implementation of RAG involves a multi-faceted architecture, harmonizing pre-training and fine-tuning. The retrieval component leverages advanced techniques such as dense vector representations and similarity scoring, ensuring efficient identification of relevant passages. The generation component harnesses the language model’s power to create contextually rich and coherent summaries.
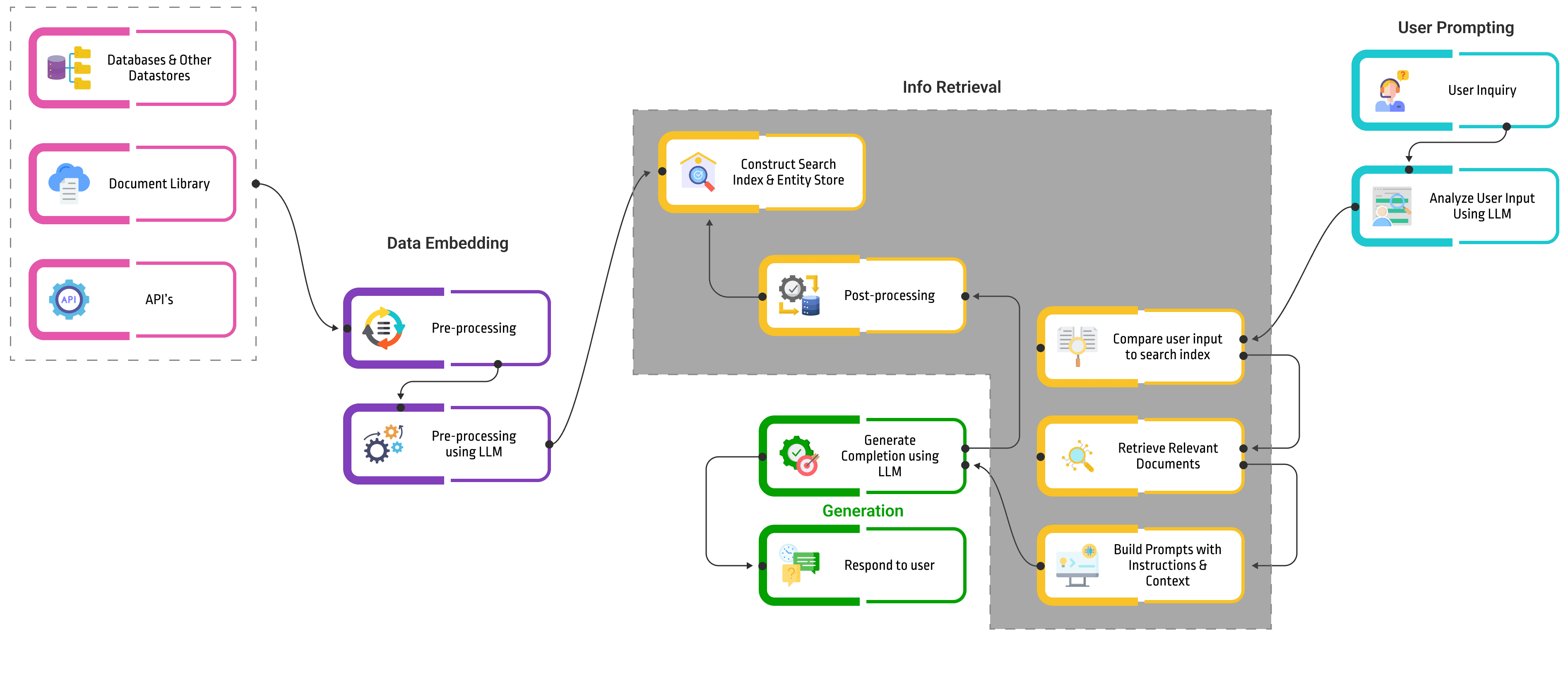
Process:
Data embedding:
- During build time, a large corpus of text data is processed by an information retrieval system.
- Each document in the corpus is converted into a numerical vector representation called an embedding.
- These embeddings are stored in a dedicated database, often a vector database for fast retrieval.
User prompting:
- At runtime, the user provides a prompt or question.
- This prompt is also converted into an embedding using the same process as the corpus documents.
Information retrieval:
- The prompt embedding is compared to the document embeddings in the database.
- The information retrieval system retrieves the top-scoring documents, also known as the most relevant passages, based on their embedding similarity to the prompt.
Generation:
- The retrieved passages are fed into the LLM, along with the original prompt.
- The LLM leverages both the prompt and the retrieved information to generate the final text output.
- This output can be anything from a factual summary of the retrieved passages to a creative story inspired by them.
RAG Flowchart
Overcoming LLM Challenges: A Case for RAG
High-Quality Training Data
RAG addresses the challenge of high-quality training data by leveraging the pre-trained knowledge of LLMs. This foundational understanding, obtained during the pre-training phase, minimizes the need for extensive domain-specific training datasets.
Contextual Relevance
LLMs often struggle with maintaining contextual relevance during information extraction. RAG’s integrated approach ensures that extracted information not only aligns with the query but also preserves the original context, addressing a critical limitation of LLMs.
Performance Enhancement Strategies
To elevate RAG’s performance, consider the following strategies:
- Continuous model training
Implement a continuous training regimen to keep the RAG model abreast of evolving language patterns and domain-specific changes. - Query expansion techniques
Explore query expansion techniques to refine the retrieval process. Techniques like semantic expansion and synonym enrichment enhance the model’s ability to retrieve relevant information.
Exploring Advanced Retrieval Methods
In the pursuit of efficient information retrieval, various methods complement RAG’s capabilities:
1. Vector Databases – Pinecone, Chroma
Vector databases, exemplified by Pinecone and Chroma, play a pivotal role in enhancing retrieval efficiency. These databases store and retrieve high-dimensional vectors, optimizing the search for relevant document passages.
2. FAISS (Facebook AI Similarity Search)
FAISS, developed by Facebook AI, is a high-performance library for similarity search and clustering. Integrating FAISS with RAG enhances the speed and accuracy of information retrieval, especially in large document corpora.
3. Lanchain for Secure Retrieval
Lanchain introduces a layer of security to retrieval, crucial in scenarios where data confidentiality is paramount. By integrating Lanchain with RAG, businesses can ensure secure and compliant information access.
Applications of LLM-Based Document Extraction
LLMs and their advanced document extraction capabilities have transcended traditional boundaries, finding applications across various industries. While document summarization and information extraction are crucial, exploring alternative applications unveils the true breadth of LLM’s transformative influence.
Automated Contract Review
Legal teams can leverage LLM-based document extraction for automated contract review. The technology ensures that no vital clauses are overlooked, reducing the risk of legal oversights and enhancing the efficiency of contract management.
Customizable Chatbots
By integrating LLM-based document extraction with chatbots, businesses can create intelligent virtual assistants capable of understanding and responding to user queries with unparalleled accuracy. This leads to improved customer service and streamlined communication.
Financial Document Analysis
LLMs prove invaluable for analyzing intricate financial documents. From deciphering complex investment reports to extracting vital information from financial statements, LLM-based document extraction enhances the efficiency of financial analysis and decision-making.
Healthcare Data Integration
LLMs play a pivotal role in integrating and extracting insights from vast healthcare datasets. By navigating through patient records, medical research papers, and clinical notes, LLM-based document extraction contributes to streamlined healthcare data management and improved patient care.
Regulatory Compliance Management
Ensuring regulatory compliance is a daunting task for businesses. LLM-based document extraction aids in monitoring and managing compliance by sifting through legal and regulatory documents, extracting relevant information, and facilitating prompt adherence to changing regulations.
Scientific Research Analysis
Researchers and scientists leverage LLM-based document extraction for analyzing vast volumes of scientific literature. It aids in identifying trends, summarizing research findings, and extracting key insights, facilitating faster literature reviews and knowledge discovery.
Future Horizons and Emerging Trends
As LLM-based document extraction continues to evolve, the future holds exciting possibilities. The integration of multimodal capabilities, combining text and images, promises a new dimension in information processing. Additionally, advancements in unsupervised learning techniques are poised to enhance the model’s ability to handle diverse data with minimal human intervention.
LLM-based document extraction and its ability to transform information retrieval and generation has redefined the way businesses manage documents, paving the way for a future where efficiency and accuracy reign supreme.
DeepLobe: Pioneering the Future of Document Intelligence
At DeepLobe, we’re at the forefront of this transformative journey. Our cutting-edge solutions leverage LLM-based document extraction to redefine how businesses manage and extract insights from their documents. As we embrace the evolving landscape of information retrieval, DeepLobe is committed to empowering businesses with efficiency, accuracy, and a vision of a document-centric future.
Embark on the Document Revolution with DeepLobe!
Ready to revolutionize your document management? Explore the power of DeepLobe’s document extraction solutions. Visit DeepLobe and witness the future of document intelligence.
